







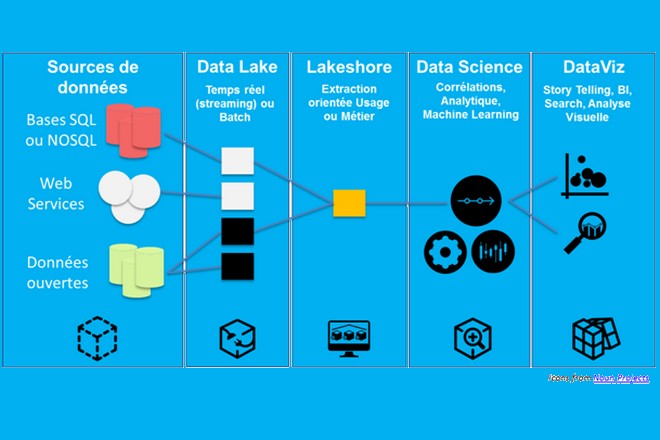
Le Big Data devient synonyme de Hadoop lorsque l’on parle de solution informatique. C’est ce qu’a confirmé Vincent Heuschling, DG de la société de conseil Affini-Tech lors du salon Open World Forum, organisé à Montrouge (92), le 4 octobre 2013.
Hadoop s’impose comme la solution idéale pour monter en charge face à la croissance des volumes de données. Autre atout de Hadoop : « Il est piloté par la communauté Open Source » souligne Vincent Heuschling.












« Contrairement à SQL, où les performances s’écroulent passé une certaine charge, ou aux solutions MPP (Massively Parallel Processing), les solutions à base d’Hadoop montent en puissance sans souci de charge » a-t-il ajouté.
Afin de traiter une grande masse d’informations, Hadoop dispose d’un système de fichiers distribué, HDFS qui permet de gérer des capacités allant de quelques Go à plusieurs Po. Hadoop s’accompagne de MapReduce, qui permet de distribuer le calcul dans le Cluster Hadoop. L’écosystème est également très riche en outillage ETL (Extract Transform and Load).
« Le Big Data, c’est beaucoup de données avec une faible valeur » décrit Vincent Heuschling. Hadoop permet de répondre ainsi aux besoins d’analyse de plusieurs centaines de dimensions pour connaître un client, et de traiter tout type de données : texte, logs, images, vidéos ou sons, le tout avec des réponses dans la minute. Il permet également de prendre en charge des données dont on ne sait pas ce qu’elles seront dans six mois, a-t-il conclu.
Top lectures en ce moment
-

Les personnages de Disney pourront être utilisés dans des vidéos créées par l...
-

Livraison en 1 heure par Carrefour : une créa publicitaire réalisée avec une IA...
-

IA générative : pourquoi Carrefour privilégie l’approche Top-Down et garde lR...
L’actualité de la transformation























L'IA clé de nos besoins vitaux dans l'eau, l'électricité et le gaz

Marchés de l’eau : l’IA générative arrive dans les réponses aux appels d’offres des collectivités
Saur, spécialiste de la distribution d’eau potable, fait évoluer son processus de réponse aux appels d’offres des collectivités et des industriels en y injectant de l’IA géné…

Stockage de l’électricité : l’IA générative outil d’accélération clé chez Engie
Le stockage de l’électricité est un enjeu stratégique. Engie s’y attelle et mobilise pour cela l’IA générative de type RAG, c'est-à-dire basée sur le traçage des documents source. …

Nouvelle donne dans le gaz naturel : GRDF s’adapte en utilisant l’IA
GRDF, leader de la distribution du gaz naturel en France, affine sa stratégie d’IA. Il s’appuie sur des serveurs internes pour la confidentialité des données de ses clients. GRDF c…
Et vous, qu’en pensez-vous ?
Une idée, une réaction, une question ? Laissez-nous un mot ci-dessous.
Je réagis à cet article